-
[ETC] 알고계셨나요? 당신의 10초.jpg2014.10.15 PM 04:25


프로젝트 구텐베르크
엄청 좋은취지인 것 같아요.
이게 사실은 '개구라' 라고 판명난다면 짜증날 것 같지만
아무튼 뭔가 엄청 멋지군요!!
댓글 : 26 개
- 루리웹-000000000
- 2014/10/15 PM 04:33
와! 이거진짜 대박이네요!
- 비스트퓨리
- 2014/10/15 PM 04:34
진짜라면...개 멋있다...
- 골드펜슬
- 2014/10/15 PM 04:34
뭔가 컴퓨터가 판독 못하는 이미지 자체를 캡쳐해 서버에 올릴 인건비면 그냥 단어 해석을 이미 했을 것 같은데...
게다가 정확도는 어떻게 판단하죠? 쉽게 믿기는 어렵네요.
게다가 정확도는 어떻게 판단하죠? 쉽게 믿기는 어렵네요.
- 김깅가낭
- 2014/10/15 PM 04:35
구라인듯하내요 그럼 저거 오타치거나
구라로 입력해도 회원가입 된다는건대
구라로 입력해도 회원가입 된다는건대
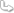
- 상식사회
- 2014/10/15 PM 04:39
예 그렇습니다. 왼쪽 문자는 정확히 입력하지 않아도 상관없습니다.
- jaekyuchoi
- 2014/10/15 PM 04:39
그래서 오른쪽 꼬부랑 글씨가 그 역할을 하는거잖아요.
- 사울팽
- 2014/10/15 PM 04:42
오타로 입력해도 상관이 없다면 서버에서 저걸 종합해서 가장 많이 입력한 단어로 이해한다는건데.
그러면 이론상 틀릴수도 있눈거네요. 맞게 입력한 사람보다 똑같은 오타로 틀린 사람이 더 많으면.
그러면 이론상 틀릴수도 있눈거네요. 맞게 입력한 사람보다 똑같은 오타로 틀린 사람이 더 많으면.
- kungfu45
- 2014/10/15 PM 04:35
아 진짜??? 이거 해외쪽 ㅇㅇ자료 구할 때 많이 해봤는데....ㅋ
- 두치와볶음
- 2014/10/15 PM 04:36
오옹...
저거 많이 보던건데... *('~ '*
저거 많이 보던건데... *('~ '*
- Biya.
- 2014/10/15 PM 04:38
뭔가 좀 이상한게....그렇다면 왼쪽에 있는건 틀린답으로 쳐도 가입이 된다는 건가요?
- NuguriX
- 2014/10/15 PM 04:53
왼쪽꺼는 틀려도 괜찮은데 오른쪽에 나온거는 맞아야 통과가 될거에요~
- KooLucK.
- 2014/10/15 PM 04:40
뭐여 진짜여???
- 루리웹-1725462382
- 2014/10/15 PM 04:41
똑같은 단어를 몇사람에게 같이 돌려서 훨씬 많이 동일한 답이 나오면 그게 답이라고 볼수 있겠지요(이를테면 10사람한테 같은 단어를 던지고 9사람이 같은단어를 뽑는식으로.) 스팸막기용은 별도의 단어가 따로 있다고 나와있구요.
기술적으로 불가능하지는 않을거같긴한데, 저 단어를 일일이 이미지화 시키는 노력이라면 그노력할 시간에 직접 보는게 낫지않나요?
기술적으로 불가능하지는 않을거같긴한데, 저 단어를 일일이 이미지화 시키는 노력이라면 그노력할 시간에 직접 보는게 낫지않나요?
- 비스트퓨리
- 2014/10/15 PM 04:44
애초에 책을 디지털 스캔하는 과정에서 무의미한 단어로 인식되는 부분만 따로 저장하도록 만든다면
충분히 가능하지 않을까요? 그정도는 충분히 자동화할 수 있을 것 같은데.
충분히 가능하지 않을까요? 그정도는 충분히 자동화할 수 있을 것 같은데.
- 물곰탱
- 2014/10/15 PM 04:45
헐 ?!?!?!?!?!
- rule-des
- 2014/10/15 PM 04:49
어...? 저게 저거였음?
- 원자력장판
- 2014/10/15 PM 04:49
http://www.gutenberg.org/
여기가 홈페이지인듯
여기가 홈페이지인듯
- 흠냐뤼
- 2014/10/15 PM 04:50
쩐다 저런 비밀이 숨어있었다니
- 가마굴
- 2014/10/15 PM 04:52
이거 대충 맞을걸요? 캡차중에 아무 글 안달아도 넘어가는 경우가 있긴 함...
하지만 인류 발전을 위해서 써줘야지
하지만 인류 발전을 위해서 써줘야지
- 로리팝
- 2014/10/15 PM 04:53
어디서 이런 쌩구라를ㅋㅋ 하고 리캡차랑 프로젝트 구텐베르그 찾아보니까 진짜네요;
저런 이유로 리캡차 플러그인도 공짜!
저런 이유로 리캡차 플러그인도 공짜!
- 남제비
- 2014/10/15 PM 05:02
쩐다
- 소네 미유키
- 2014/10/15 PM 05:04
와 예전부터 대체 저 많은 이미지는 어디서 긁어온거야 시간 낭비 보소 했는대
저런곳에 쓰였군아
저런곳에 쓰였군아
- 에이다웡
- 2014/10/15 PM 05:19
와 ㅋㅋㅋㅋㅋㅋㅋ 이건 레알 마이피지만 오른쪽 갔으면 좋겠다
- 비추버튼
- 2014/10/15 PM 06:39
스캔이야 스캔이고 그야말로 글자별로 이미지 자르는건 거의 자동화가 가능할것같은데요..
- 학냉이
- 2014/10/15 PM 06:46
저거 진짜로 있는거임 TED 강의 영상 있음
아래 누군가가 달아주겟지
아래 누군가가 달아주겟지
- 학냉이
- 2014/10/15 PM 08:33
http://www.ted.com/talks/view/lang/ko//id/1295
user error : Error. B.