-
[공부 - PG] OCR Tesseract 공부중...2020.10.15 PM 10:12
대충 처음 목표는 스도쿠 화면 인식해서
자동으로 풀어 주는 프로그램 만들어 주는 프로그램 만들려고 준비 했는데
결론적으로는 포기 했음...
처음 목표 했던 환경은
OS 리눅스(UBUNTU)
언어 C#(Dotnet Core)
GUI Gtk
추가 라이브러리 : OpenCV(?)
리눅스에서 GTK든 OpenCV든 C++로 만들어진 프로그램이라
각각 라이브러리 랩퍼써서 어쩌고는 뭐... 다 넘어가고...
처음에는 숫자 한글자 정도는 OpenCV에서 읽어 줄거라고 말도 안되는 착각을 하고 시작
스도쿠 푸는거야 옛날에 만들었고 구글에서 SUDOKU Solve 처음 넘치게 나오고
일단 Gtk도 처음이라 그냥 윈도우 .Net으로 만들면 그냥 끝나는 걸
오랜 지병인 중2병 때문에 리눅스로 해야 한다고 했다가 시행착오는 하다가 완성
스도쿠 문제를 인식 하려면 문제의 숫자를 인식 해야 하는데...
무료로 할 수 있는 OCR 라이브러리는 Tesseract 밖에 없다는 걸 알고
추가로 공부 시작함...
그런데 문제는 Nuget에서 Tesseract 검색해서 나오는 물건들은
대부분 최신 버전에 안맞고 더 중요한건 윈도우용으로 만들짐(EXE찾고 있음)

그런 의미로 Dotnet 에서 Python으로 변경
이번에도 Gtk Glade로는 투명이 안먹혀서 다시 제작
뭐 다시 만든 GUI는 창 크기 대충 맞춘 다음에 RUN 버튼
누르면 화면 캡쳐해서 그 그림의 숫자를 인식(Tessseract)
그 데이터를 바탕으로 문제를 확정하고 자동으로 품
처음 문제는 글자가 한글자 따로 있으면 인식 자체가 잘 안됨...
스도쿠 특성상 한글자 밖에 없으니 인식이 안되면 안되니까
계속 조사 해서 한글자씩 그림을 쪼개서 다시 인식했는데
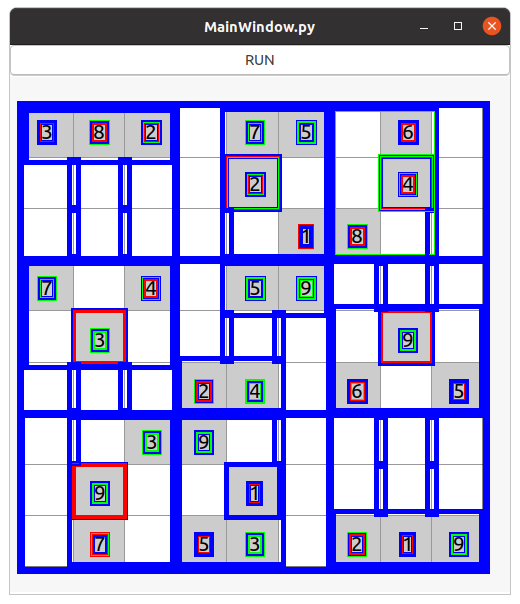
결론은 잘 안됨... 더 이상은 무리네요...
흐음... 아무튼 OpenCV랑 Tesseract 컴파일 하는 것도 시행착오 있었는데.. 그것도 너무 길어서...
결국 이정도에서 접어야 겠음... 같은 그림(글자)라도 매번 인식이 다른 것도.. 그렇고...
아무튼 OpenCV잡아 본 김에 좀 더 조사해봐야겠네요...
10월 24일 추기
무료(?) OCR로 마소 제공
윈도우 OCR도 테스트 해보니
문자 인식은 Tesseract보다 좋지만
숫자 한글자는 무리였음..
진짜 끝..
- 케형
- 2020/10/15 PM 11:06
이번에 진행했던 프로젝트에선 결국 글자들을 이미지로 준비해서 template matching 을 했었죠.
opencv_contrib 쪽에도 텍스트 인식 관련 모듈이 있으니 한 번 테스트 해보시면 좋을 것 같네요
- 이상한
- 2020/10/15 PM 11:22
user error : Error. B.