-
[월가 아재] [월가아재 시즌3 - 9편] 엔비디아 투자자라면 꼭 알아야할 AI 이야기 [상편]2024.07.13 PM 09:22
■ Nvdia 투자자라면 꼭 알아야할 AI의 4요소
● AI 알고리즘
● 데이터
● GPU (대규모 병렬 연산)
● 에너지
■ 짤막한 AI의 역사
AI의 시작 ~ 1차 AI 겨울
● 1957년, 최초의 인공신경망 알고리즘 - Perceptron (퍼셉트론)
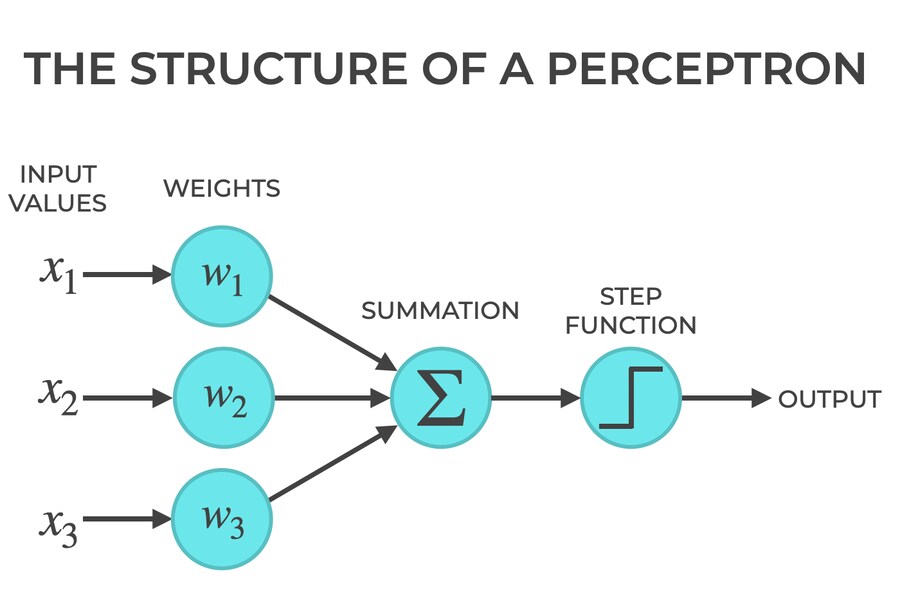
퍼셉트론 알고리즘 = 주어진 데이터를 잘 구분하는 선을 학습하는 알고리즘
● 민스키 & 페퍼트 : 퍼센트론이 XOR 문제를 풀 수 없음을 수학적으로 증명
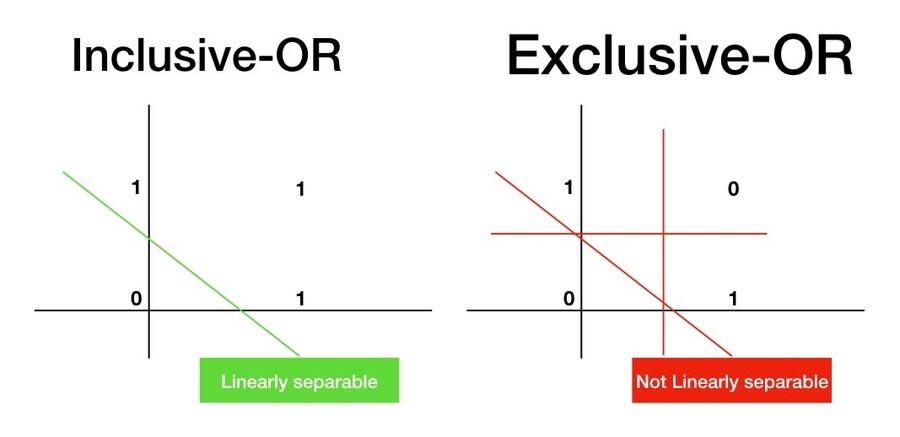
● 미 국방부의 2천만 달러 지원금 전격 중단 → 1차 AI 겨울
80년대의 부흥 ~ 2차 겨울
● 전문가 시스템, Knowledge-based AI, IF-THEN 규칙...
● 지식 베이스 구축에 드는 비용, 규칙 기반 AI의 유연성 한계 → 2차 AI 겨울
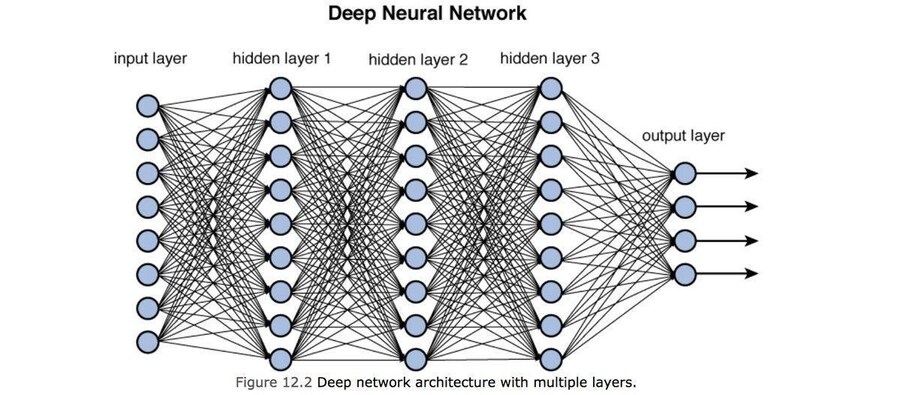
■ 딥러닝의 거장들
딥러닝의 아버지 - 제프리 힌튼
1950년대 퍼셉트론에서 발전
● XOR 문제 → 하나가 아닌 여러 겹의 퍼셉트론을 연결하여 해결 → 딥러닝
● 수십 년간 역전파 (Backpropagation) 알고리즘, Vanishing Gradient 문제 등 해결
● 제프리 힌튼, 얀 르쿤, 조슈아 벤지오 등
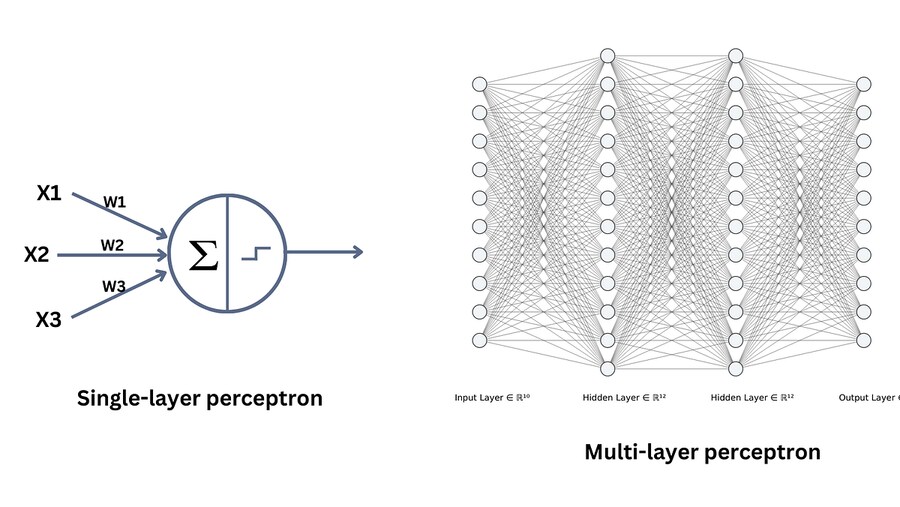
딥러닝 = 여러 레이어를 겹겹이 깊게 쌓음
■ 왜 2010년대에 들어서야 꽃을 피웠을까?
1950년대부터 발전한 알고리즘이, 왜 2010년대 들어서야 비로소 결실을 맺었을까?
● 데이터 & GPU
AI 모델링과 데이터
● 단순한 현상일수록 데이터가 적게 필요, 복잡한 현상일수록 데이터가 많이 필요
● 복잡한 모델에 데이터가 너무 적으면, 샘플 데이터에만 맞는 모델을 학습하는 과최적화가 발생
● 인간의 언어, 이미지 인식 → 엄청 복잡한 현상 → 엄청 복잡한 모델 → 엄청 많은 데이터 필요
● 2000년대 후반부터 인터넷의 발달로 텍스트/이미지 테이터가 폭발적으로 생산됨
빅테이터 기업들의 약진
● 구글 - 검색 테이터, 아마존 - 구매 및 선호 데이터 , 메타 - SNS 데이터
● 일론 머스크의 트위터 인수
■ 데이터 다음의 병목: 연산
알고리즘 발달 → 데이터 병목 → 빅 데이터 시대 → 컴퓨터 연산 능력의 병목

과거 프로세싱 칩 대장 : 인텔
● 인텔의 주력인 CPU : 엄청나게 우수한 코어 8~32개 (소수의 코어 하나하나가 복잡한 연산을 수행)
● 엔비디아의 주력인 GPU : 모니터 픽셀을 병렬 계산하기 위한 단순한 코어 수백, 수천 개 (사칙 연산 수준의 쉬운 연산을 대규모 병렬 처리)
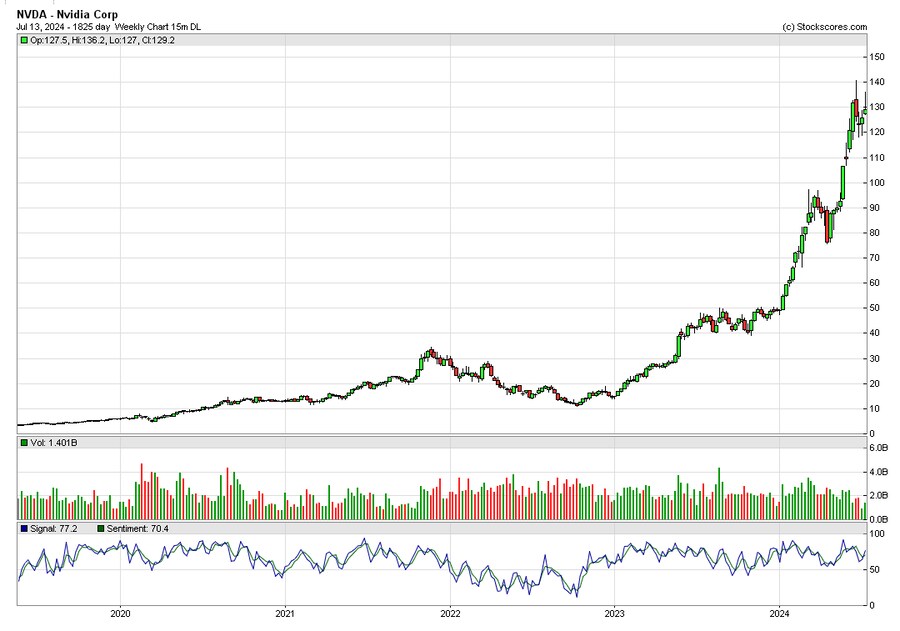
● 딥러닝은 GPU로 연산하기 좋은 구조 → CPU보다 수십 배 빠른 속도 → GPU 수요 폭발 (엔비디아 주가 폭등)
● 2016년 ImageNet 파라미터 2천만개 → GPT3 1750억개 (복잡도 10,000배)
■ 킹반영
이 내용은 2024년에는 이미 다 반영되어 있음
다음 시간
● 알고리즘 → 데이터 → GPU 다음은 무엇일까?
user error : Error. B.