Func(long long* a)
{
for(long long i = 0; i < 10000000; ++i)
{
++(*a);
}
}
위와같이 함수에서 주소를 매개변수로 받아와 값을 증가시킬 때,
스레드를 사용하지 않았을 때와, 복수의 스레드를 사용했을 경우(서로 다른 변수주소를 매개변수로 주므로 경쟁상태는 일어나지 않음.)
속도차이가 10배정도로 심하게 많이 났습니다.(복수의 스레드를 사용한 경우가 느렸습니다.)
Func(long long* a)
{
long long b = 0;
for(long long i = 0; i < 10000000; ++i)
{
++b;
}
*a = b;
}
위와같이 반복연산에 스레드 내부데이터를 사용했을 경우엔 약간 느린정도인 것을 보면, 외부자원에 대한 스레드에서의 연산이 느린것으로 보이는데
(동일한 스레드 외부 데이터인 전역변수에 대해서도 같은 상황. 예외로 스레드를 하나만 생성할 경우 발생하지 않았습니다.)
왜 그런지 아시는분 혹시 설명해 주실수 있을까요...
//추가
로그 첨부합니다. i5 6세대 4코어 CPU, 윈도우10 1903, VS2017이며, Release로 디버깅하였습니다.
함수호출의 경우 큰 차이는 없었고, 좌측상단의 경우 환경에 따라 각 스레드별 40초까지도 늘어났습니다.
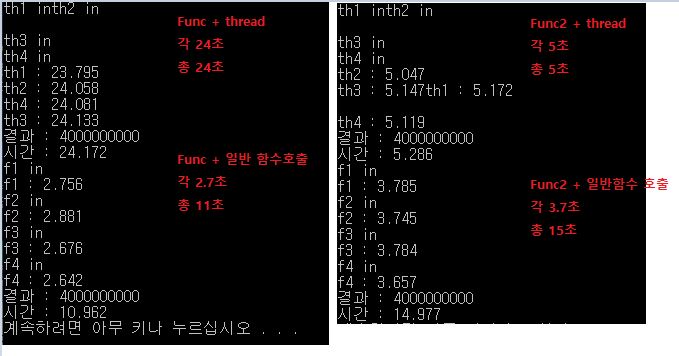

그러니까 스레드가 공용자원에 엑세스 해서 느려진게 아니라,
스레드간 전환(컨텍스트 스위칭)따위에 CPU자원을 소모하고 있는걸로 보이네요