

세계적인 인공지능 기업 세 곳이 최신 모델을 개발하려는 고비용 투자에서 점점 감소하는 성과를 마주하고 있습니다.

ChatGPT 가상 비서 로고. 사진: Andrey Rudakov/Bloomberg
2024년 11월 13일 오후 7시 GMT+9
작성자: Rachel Metz, Shirin Ghaffary, Dina Bass, Julia Love
---
OpenAI는 중요한 이정표를 앞두고 있었습니다. 이 스타트업은 9월에 ChatGPT 기술을 이전 버전보다 크게 발전시키고 인간을 능가하는 강력한 AI 목표에 더 가까워질 것을 기대하며 대규모 신형 AI 모델의 초기 훈련 라운드를 완료했습니다.
하지만 내부적으로 ‘오리온(Orion)’으로 알려진 이 모델은 회사가 기대한 성능을 충족하지 못했다고 이 사안에 정통한 두 명의 관계자는 익명을 조건으로 전했습니다. 예를 들어 오리온은 여름 말경, 훈련되지 않은 코딩 질문에 답하려 할 때 어려움을 겪었다고 관계자들은 밝혔습니다. 전반적으로 오리온은 기존 GPT-3.5에서 GPT-4로의 업그레이드만큼 큰 도약을 이루지 못한 것으로 평가되었습니다.
OpenAI만이 최근 난관에 부딪힌 것은 아닙니다. 지난 몇 년 동안 점점 더 정교한 AI 제품을 빠르게 출시해 온 주요 AI 기업 세 곳이 이제는 신형 모델을 개발하는 데 드는 막대한 비용에도 불구하고 점점 낮아지는 성과를 보이고 있습니다.Alphabet Inc.의 Google은 차세대 Gemini 소프트웨어가 내부 기대에 미치지 못하고 있으며, Anthropic 또한 오래 기다려온 Claude 모델 3.5 Opus의 출시 일정이 지연되고 있는 상황입니다.
이들 기업은 몇 가지 난관에 직면해 있습니다. 더 발전된 AI 시스템을 구축하는 데 사용할 수 있는 인간이 제작한 고품질의 새로운 학습 데이터원을 찾는 것이 점점 어려워지고 있습니다. 관계자들에 따르면, 오리온의 코딩 성능이 기대에 미치지 못한 이유 중 하나는 충분한 코딩 데이터가 부족했기 때문이라고 합니다. 또한, 소폭의 개선만으로는 새로운 모델을 구축하고 운영하는 데 드는 엄청난 비용을 정당화하거나, 제품을 주요 업그레이드로 브랜딩하는데에 따른 기대치에 부응하기 어려울 수 있습니다.
향후 모델 개선 가능성은 여전히 존재합니다. OpenAI는 오리온을 몇 달간의 '사후 훈련' 과정을 거치게 하고 있다고 한 관계자가 밝혔습니다. 이 과정은 새 AI 소프트웨어를 공개하기 전에 통상적으로 거치는 단계로, 인간의 피드백을 반영해 응답을 개선하고 사용자와 상호작용할 모델의 톤을 다듬는 등의 작업이 포함됩니다. 오리온은 아직 OpenAI가 생각하는 공개 기준에 미치지 못해, 한 관계자에 따르면 출시는 내년 초로 미뤄질 전망입니다.
이 같은 문제는 OpenAI가 2년 전 ChatGPT를 출시한 이후 실리콘밸리에 자리잡은 믿음에 반하는 것입니다. 업계는 더 많은 데이터, 더 큰 모델, 그리고 더 많은 컴퓨팅 파워가 AI의 강력한 성장을 이끌 것이라는 ‘스케일링 법칙’에 베팅해 왔습니다.
최근의 문제들은 AI에 대한 막대한 투자와 이들 기업이 공격적으로 추구하는 최종 목표인 ‘일반 인공지능(AGI)’의 실현 가능성에 대한 의문을 불러일으킵니다. 일반적으로 AGI는 여러 지적 과제에서 인간을 능가하거나 인간과 동등한 능력을 가진 가상의 AI 시스템을 의미합니다. OpenAI와 Anthropic의 CEO들은 이전에 AGI가 몇 년 내에 달성될 수도 있다고 언급한 바 있습니다.
AI 스타트업 허깅페이스(Hugging Face)의 최고 윤리 과학자인 마가렛 미첼은 “AGI 거품이 조금씩 꺼지고 있다”고 말했습니다. “AI 모델이 다양한 작업을 잘 수행하게 하려면 ‘다른 훈련 접근법’이 필요할 수 있다는 점이 분명해지고 있다”고 그녀는 전했습니다. 이는 다수의 인공지능 전문가들이 Bloomberg 뉴스에 전한 의견과 일치합니다.

AI 스타트업 허깅 페이스의 최고 윤리 과학자인 마거릿 미첼은 "AGI 거품이 꺼지고 있다"고 말했습니다. 사진: Chona Kasinger/Bloomberg
Google DeepMind의 대변인은 성명을 통해 “Gemini의 발전에 대해 매우 만족하며 준비가 되면 더 많은 정보를 공유할 것”이라고 밝혔습니다. OpenAI는 논평을 거부했고, Anthropic은 코멘트를 거부했지만 CEO 다리오 아무데이의 인터뷰가 담긴 다섯 시간 분량의 팟캐스트를 Bloomberg 뉴스에 추천했습니다.
아무데이는 팟캐스트에서 “사람들은 이를 스케일링 법칙이라고 부르지만, 그것은 잘못된 명칭입니다. 이는 보편적 법칙이 아닙니다. 경험적인 규칙에 불과합니다. 나는 이러한 법칙이 지속될 가능성에 베팅하지만, 확신할 수는 없습니다.”라고 말했습니다.
그는 향후 몇 년 내에 더 강력한 AI 개발 과정이 “탈선”할 수 있는 “여러 요인”이 있으며, 특히 “데이터가 고갈될 수 있다”는 가능성을 지적했습니다. 하지만 그는 AI 기업들이 이러한 장애물을 극복할 방법을 찾을 것이라며 낙관적인 입장을 밝혔습니다.
성능 한계
ChatGPT와 경쟁 AI 챗봇의 핵심 기술은 소셜 미디어 게시물, 온라인 댓글, 책, 그리고 웹상에서 자유롭게 수집된 다양한 데이터를 기반으로 구축되었습니다. 이러한 데이터로 흥미로운 에세이와 시를 작성할 수 있는 제품을 만들기에는 충분했습니다. 하지만 일부 기업이 목표로 하는 것처럼 노벨상 수상자보다 더 뛰어난 인공지능 시스템을 구축하기 위해서는 위키피디아 게시물이나 유튜브 자막 이상의 데이터가 필요할 수 있습니다.
특히, OpenAI는 고품질 데이터 확보를 위한 일부 필요를 충족하고, 생성형 AI 제품 개발에 사용된 데이터에 대해 출판사와 예술가들이 제기하는 법적 압력에 대응하기 위해 출판사와 계약을 체결했습니다. 일부 기술 회사들은 수학과 코딩과 같은 특정 주제에 대한 전문 지식을 가지고 데이터에 라벨을 붙일 수 있는 대학원 학위를 소지한 사람들을 고용하고 있습니다. 이는 이러한 시스템이 특정 주제에 대해 더 나은 답변을 제공할 수 있도록 하기 위함입니다.
이러한 노력은 웹에서 데이터를 간단히 수집하는 것보다 느리고 비용이 많이 드는 과정입니다. 또한, 일부 기술 회사들은 실제 사람이 만든 콘텐츠를 모방한 컴퓨터 생성 이미지나 텍스트와 같은 합성 데이터를 이용하려 하고 있습니다. 그러나 이 또한 한계가 있습니다.
New Enterprise Associates의 AI 전략 책임자이자 마이크로소프트 전 부최고기술책임자(CTO)인 리라 트레티코프(Lila Tretikov)는 “이제는 양보다는 데이터의 질과 다양성이 중요합니다. 합성적으로 양을 만들어낼 수는 있지만, 특히 언어와 관련해서는 인간의 지침 없이 고유하고 높은 품질의 데이터를 얻기가 어렵습니다.”라고 말했습니다.
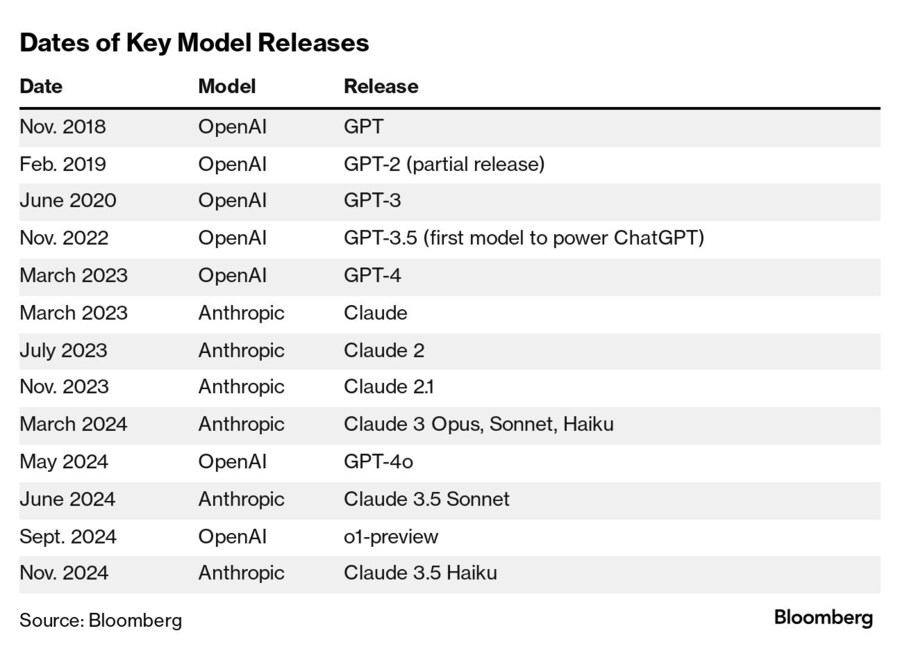
주요 모델 출시 일정
그럼에도 불구하고 AI 기업들은 더 많은 것이 더 낫다는 방식을 계속 추구하고 있습니다. 인간 지능에 근접한 제품을 만들기 위해 기술 기업들은 새로운 모델을 훈련하는 데 사용하는 컴퓨팅 파워, 데이터, 그리고 시간을 계속해서 증가시키고 있으며, 이로 인해 비용도 증가하고 있습니다. 아모데이(Amodei)는 기업들이 올해 최신 모델을 훈련하는 데 1억 달러를 쓸 것이며, 앞으로 몇 년 동안 그 금액이 1천억 달러에 이를 것이라고 밝혔습니다.
비용이 증가함에 따라 개발 중인 새로운 모델에 대한 기대와 기대치도 높아지고 있습니다. 매사추세츠주 월섬에 있는 벤틀리 대학교의 수학과 노아 지안시라쿠사(Noah Giansiracusa) 부교수는 AI 모델이 계속 개선될 것이라고 예측했지만, 그 속도는 의문이라고 말했습니다.
“우리는 짧은 기간 동안 매우 빠른 발전 속도에 매우 흥분했습니다.”라고 그는 말했습니다. “하지만 그것이 지속 가능하지는 않았습니다.”
실리콘밸리의 딜레마
최근 몇 달 동안 실리콘밸리 내에서 이 딜레마가 명확해졌습니다. 3월에 Anthropic은 세 가지 새로운 모델을 출시했으며, 그중 가장 강력한 모델인 '클로드 오푸스(Claude Opus)'가 대학원 수준의 추론과 코딩 같은 주요 평가 기준에서 OpenAI의 GPT-4와 구글의 제미니(Gemini) 시스템을 능가했다고 발표했습니다.
그 후 몇 달 동안 Anthropic은 다른 두 개의 클로드 모델을 계속 업데이트했지만, 오푸스는 업데이트하지 않았습니다. 독립 AI 연구자인 사이먼 윌리슨(Simon Willison)은 "모두가 기대했던 모델은 바로 그것이었습니다"라고 말했습니다. 10월이 되자 윌리슨과 다른 업계 관계자들은 '3.5 오푸스'에 대한 언급, 예를 들어 '올해 후반에 출시 예정'이라거나 '곧 출시'라는 문구가 회사 웹사이트의 일부 페이지에서 사라진 것을 발견했습니다.
익명을 요구한 두 명의 관계자에 따르면, 경쟁사들과 마찬가지로 Anthropic도 3.5 오푸스를 개발하는 과정에서 비공개로 어려움을 겪고 있는 것으로 알려졌습니다. 한 관계자는 Anthropic이 3.5 오푸스를 훈련한 후, 성능이 이전 버전보다 더 나아졌지만 모델의 크기와 구축 및 운영 비용을 고려했을 때 기대에 미치지 못했다고 말했습니다.
Anthropic 대변인은 오푸스 관련 문구를 웹사이트에서 삭제한 이유가 사용 가능하고 평가된 모델만을 보여주기 위한 마케팅 관련 결정이었다고 설명했습니다. '3.5 오푸스'가 올해 안에 출시될지에 대한 질문에는 CEO 아모데이의 팟캐스트 발언을 인용했습니다. 인터뷰에서 아모데이 CEO는 해당 모델의 출시를 여전히 계획 중이라고 밝혔지만, 구체적인 일정에 대해서는 명확히 답변을 피했습니다.
 Anthropic의 CEO 다리오 아모데이는 향후 몇 년 내에 더 강력한 AI에 도달하는 과정에서 “방해가 될 수 있는 많은 요소들이 있다”고 말했습니다. 그는 “우리가 사용할 데이터가 고갈될 수도 있다”고 덧붙였습니다. 사진: Benjamin Girette/Bloomberg
Anthropic의 CEO 다리오 아모데이는 향후 몇 년 내에 더 강력한 AI에 도달하는 과정에서 “방해가 될 수 있는 많은 요소들이 있다”고 말했습니다. 그는 “우리가 사용할 데이터가 고갈될 수도 있다”고 덧붙였습니다. 사진: Benjamin Girette/Bloomberg
기술 회사들은 오래된 AI 모델을 추가 개선해 계속 제공할지, 아니면 성능이 크게 향상되지 않을 수도 있는 비용이 많이 드는 새로운 버전을 지원할지에 대해 고민하기 시작했습니다.
구글은 자사의 주력 AI 모델인 제미니에 업데이트를 적용해, 사람의 이미지를 생성하는 기능을 복구하는 등 더 유용하게 만들었으나 기본 모델의 품질에는 큰 혁신을 도입하지 않았습니다. 반면 OpenAI는 올해 ChatGPT와의 음성 대화를 더욱 자연스럽게 할 수 있는 새로운 버전의 음성 비서 기능 등 비교적 점진적인 업데이트에 주력하고 있습니다.
최근 OpenAI는 'o1'이라는 모델의 미리보기 버전을 출시했으며, 이는 질의에 답변하기 전에 추가 시간을 들여 답변을 계산하는 과정을 통해 더 나은 답변을 제공하는, 회사가 '추론'이라 부르는 방식입니다. 구글도 유사한 접근 방식을 통해 더욱 복잡한 질의를 처리하고 시간이 지남에 따라 더 나은 답변을 제공하는 것을 목표로 하고 있습니다.
기술 기업들은 또한 자신들의 소중한 컴퓨팅 자원을 더 큰 모델의 개발 및 실행에 지나치게 할애할 경우 얻을 수 있는 성과에 비해 손실이 더 클 수 있다는 점에서 중요한 절충에 직면하고 있습니다.
OpenAI의 CEO 샘 알트먼(Sam Altman)은 최근 Reddit의 '무엇이든 물어보세요(Ask Me Anything)' 세션에서 질문에 답하며 “이 모든 모델은 매우 복잡해졌고 우리가 원하는 만큼 여러 작업을 동시에 진행하기가 어려워졌다”고 언급했습니다. ChatGPT를 개발한 OpenAI는 “많은 제약과 어려운 결정”을 직면하고 있으며, 가용 컴퓨팅 자원을 어디에 활용할지에 대한 결정을 해야 한다고 덧붙였습니다.
알트먼은 OpenAI가 올해 말에 “매우 좋은” 출시 제품을 선보일 예정이지만, 많은 AI 업계 관계자들이 기대하는 GPT-5는 포함되지 않을 것이라고 밝혔습니다. GPT-4가 출시된 지 18개월 이상 지났기 때문에 많은 이들은 OpenAI가 다음 대규모 모델 출시를 위해 GPT-5라는 이름을 사용할 것으로 예상하고 있습니다.
구글과 Anthropic처럼 OpenAI도 이제 모델의 크기보다는 항공편 예약이나 이메일 전송을 대신해주는 에이전트라고 불리는 AI 도구군을 포함한 새로운 사용 사례로 관심을 옮기고 있습니다. 알트먼은 Reddit에서 “더 나은 모델을 계속 제공할 것”이라며, “다음 큰 돌파구처럼 느껴질 것은 에이전트일 것”이라고 언급했습니다.
