

기업, 투자자 및 사회는 인공지능으로 인한 수요 충격에 대비 중

삽화: 카롤리나 모스코소(Carolina Moscoso), 블룸버그 마켓(Bloomberg Markets) 제공
2024년 12월 13일 오후 8:00 (GMT+9)
겉보기에는 쉬워 보인다. ChatGPT에 질문을 하면 응답이 돌아온다. 하지만 그 이면을 들여다보면, ChatGPT의 요청 한 번, 혹은 Microsoft Copilot의 작업 한 건마다 방대한 자원이 소비된다는 사실을 알 수 있다. 모델을 설계하고 수정하며 훈련시키는 데 수백만 명의 사람이 투입된다. 국가를 운영할 수 있을 만큼의 테라와트시(TWh) 단위 전기가 사용된다. 전 세계에 걸쳐 자리한 데이터센터 메가캠퍼스, 전력망 네트워크와 인터넷 케이블, 그리고 물, 땅, 금속, 광물이 동원된다. 인공지능은 그 모든 것을 필요로 하며, 앞으로 더 많이 필요로 할 것이다.
연구자들은 단일 ChatGPT 요청을 처리하는 데 드는 전력이 기존의 Google 검색보다 거의 10배 더 많다고 추산했다. 일반적인 검색 엔진은 웹에서 콘텐츠를 검색하여 방대한 색인에 저장하는 방식으로 작동한다. 하지만 최신 AI 제품들은 LLM(Large Language Model, 대규모 언어 모델)로 알려진 기술에 의존한다. 이 모델들은 윌리엄 셰익스피어의 전집부터 연방준비제도(Fed)의 최신 경제 전망에 이르기까지 수십억 단어의 텍스트를 학습한다. 이를 통해 패턴과 연관성을 감지하고, 인간 행동을 모방하도록 돕는 수십억 개의 '파라미터'를 개발한다. 이러한 모델을 사용해 ChatGPT와 같은 시스템은 새로운 콘텐츠를 생성하는데, 이를 '생성형 AI(Generative AI)'라고 부른다.
AI의 높은 자원 소모량은 승자와 패자를 나누게 될 것이다. 더 많은 자원을 보유한 이들이 가장 발전된 AI 시스템을 갖출 수 있을 것이다. 이는 점점 희소해지는 자원과 반도체 접근권을 둘러싼 충돌로 이어지고 있다. 기술 기업들은 AI 개발을 보다 효율적으로 진행하기 위해 노력하고 있으며, 수십억 달러를 핵융합과 같은 대체 에너지 솔루션에 투자하고 있다. 이러한 기술은 그간 충분한 자금과 기술적 돌파구 없이 더디게 발전해왔지만, AI 산업은 이를 빠르게 활성화하고 있다. 그러나 동시에, AI의 높은 전력 수요는 전력망을 유지하기 위해 화석 연료 사용을 지속하도록 압박하고 있다. 이는 기후 변화와의 싸움에서 중요한 탄소 배출량 목표를 초과할 위험을 가중시키고 있다.
AI 구축은 투자자, 기업, 사회에 엄청난 기회를 제공하고 있지만, 위험도 존재한다. 많은 이들이 이러한 시스템이 초래할 잠재적 해악과 편향성을 우려하고 있다. 한편, 월스트리트는 AI 기술이 의미 있는 수익으로 연결되기를 기다리는 데 지쳤다. 심지어 AI 개발자들의 효율성에 대한 집중은 인프라에 과잉 투자한 이들에게는 악재로 작용할 수 있다. AI 산업이 모델을 지속적으로 운영하기 위해 요구하는 모든 것을 살펴보자.
추가로 1,000테라와트시(TWh)의 전력
AI는 주로 마더보드, 칩, 저장 장치들로 가득 찬 데이터센터에서 실행되고 운영된다. 이러한 데이터센터의 전력 수요는 현재 세계 여러 지역에서 공급 가능량을 초과하고 있다. 골드만삭스(Goldman Sachs Group Inc.)에 따르면, 2030년까지 미국 데이터센터가 전체 전력 소비의 8%를 차지할 것으로 전망된다. 이는 AI 열풍이 시작된 2022년의 비중에서 거의 3배 증가한 수치다. 골드만삭스는 이를 "한 세대 동안 전례 없던 전력 소비 증가"로 묘사했다. 스웨덴과 영국에서도 비슷한 수준의 전력 수요 급증이 예상된다. 2034년까지 데이터센터의 연간 전력 소비량은 현재 약 500테라와트시에서 1,580테라와트시를 넘어설 것으로 보이며, 이는 인도의 전체 전력 소비량과 맞먹는 수준이다.
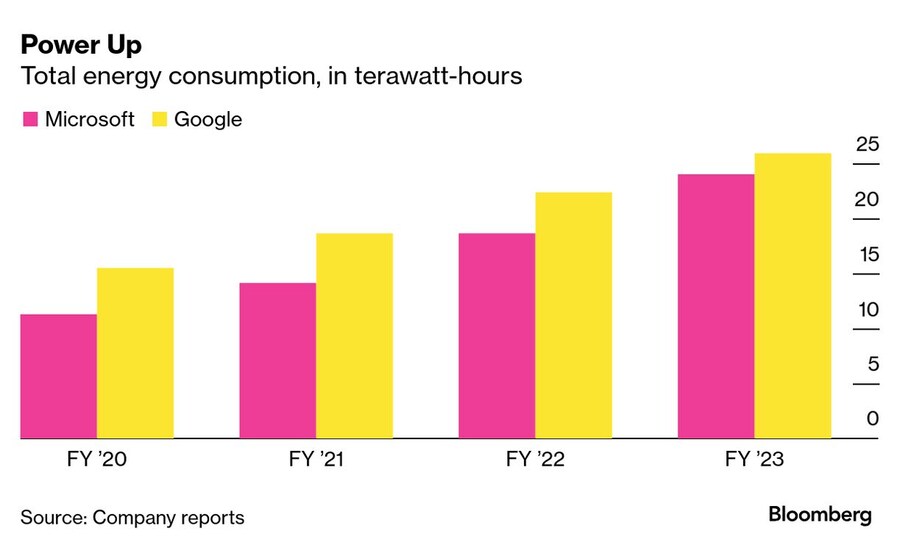
전력 수요 증가
테라와트시 단위의 총 전력 소비량
알파벳(Alphabet Inc.) 산하 구글(Google)이 운영하는 데이터센터는 2023 회계연도에 24테라와트시 이상의 전력을 소비했으며, 이는 2021년 대비 31% 이상 증가한 수치다. 마이크로소프트(Microsoft Corp.)의 전력 사용량도 이와 비슷했으며, 2년 전보다 약 70% 급증했다. 세계 최대 기술 기업들은 전력이 AI 공급망에서 가장 큰 병목 현상이 될 수 있다는 사실을 인식하고 있으며, 장기적인 전력 공급 확보를 위해 분주히 움직이고 있다.
지난 5월, 마이크로소프트와 브룩필드 자산운용(Brookfield Asset Management Ltd.)의 친환경 에너지 부문은 역대 최대 규모의 기업 청정에너지 구매 계약을 체결했다. 10월에는 세계 최대 태양광 및 풍력 발전 기업인 넥스트에라 에너지(NextEra Energy Inc.)가 2030년까지 10.5기가와트(GW)의 재생 에너지 및 에너지 저장 시설을 개발할 가능성이 있는 계약을 두 곳의 포춘 50대 기업과 체결했다고 발표했다. 흥미로운 점은 이들 기업이 기술 기업조차 아니라는 사실이다. 넥스트에라 에너지의 최고경영자(CEO) 존 케첨(John Ketchum)은 투자자들에게 "데이터센터 외의 다른 산업들도 저비용 재생에너지를 확보하기 위해 경쟁이 심화되고 있다"며 "모든 배가 밀물에 떠오르는 상황"이라고 말했다.
가능한 모든 화석 연료, 그리고 그 이상
석탄은 세계에서 가장 탄소 집약적인 에너지원 중 하나로, 여전히 전 세계 전력 공급의 약 3분의 1을 생산하는 데 사용된다. 또한 지구온난화를 유발하는 배출가스를 생성하는 천연가스는 전력의 약 20%를 공급한다. 최근 몇 년간 풍력 및 태양광 발전소가 확산되었지만, 데이터센터의 전력 수요를 충족하기 위해 공급을 안정적으로 유지할 수 있는 거대한 배터리가 없는 상황에서는 재생에너지의 간헐적인 특성이 데이터센터 운영에 문제가 되고 있다. 데이터센터는 지속적인 전력 흐름에 의존하기 때문이다.
구글(Google)이 처음 도입한 기술이 이러한 문제를 해결할 방안으로 떠오르고 있다. 이 기술은 소프트웨어를 활용해 전력망에 과잉 공급된 태양광 및 풍력을 찾아내고, 해당 지역에서 데이터센터 운영을 강화하는 방식이다. 그러나 현재로서는 사실상 유일하게 안정적이고 24시간 가동 가능한 무배출 에너지원은 핵발전이다. 이는 마이크로소프트가 지난 9월 펜실베이니아주 쓰리마일 섬(Three Mile Island) 핵발전소의 원자로를 재가동하기 위한 계약을 체결한 이유를 설명해준다. 쓰리마일 섬은 1979년 악명 높은 부분 붕괴 사고가 발생했던 곳이다. 약 한 달 뒤, 아마존(Amazon.com Inc.)은 소형 원자로 개발을 위한 세 건의 계약을 체결했으며, 구글은 모듈형 원자로를 개발하는 기업에 투자하고 그곳에서 생산되는 전력을 구매하기로 약속했다.
"제발요, 핵발전소라니요. 농담하는 거 아니죠?" 오라클(Oracle Corp.)의 회장 래리 엘리슨(Larry Ellison)은 지난 9월 애널리스트 회의에서 이렇게 말했다. "이건 완전히 허구처럼 들리지만, 실제입니다. … 이런 일이 과거에 한 번이라도 있었나요?"
현재의 100배가 필요한 전력망 용량
전력선과 변전소는 AI 체인에서 가장 과소평가된 연결 고리다. 새로운 데이터센터들은 이미 노후화되고 과부하 상태이며, 악천후에 취약한 기존 전력망에 연결되어야 한다. (허리케인 헬렌(Hurricane Helene)을 떠올려보라.) 지난 4월 열린 블룸버그 인텔리전스(Bloomberg Intelligence) 행사에서 클라우드 서비스 제공업체 CoreWeave Inc.의 공동 창립자 브라이언 벤투로(Brian Venturo)는 자신과 같은 회사들이 전력망에 큰 부담을 줄 거대한 데이터센터를 개발하고 있다고 말했다.
산업 지역의 변전소가 30메가와트의 전력을 공급한다고 가정해보자. 이 중 약 5메가와트는 해당 지역의 데이터센터가 사용하고 나머지는 다른 사무실이나 공장에 공급된다. 그런데 오늘날 CoreWeave 같은 회사들은 “나는 500메가와트를 원한다”고 요구하고 있다. “새로운 송전선을 건설해야 합니다. 새로운 변전소를 지어야 합니다.”라고 벤투로는 말했다. 그리고 이 변전소에는 변압기가 필요하며, 이는 몇 년 전에 미리 주문해야 할 수도 있다.
그리고 이 모든 것은 500메가와트를 충당하기 위한 것이다. OpenAI의 공동 창립자 겸 CEO 샘 올트먼(Sam Altman)은 데이터센터 하나에 5,000메가와트가 필요할 수 있다고 언급했다. 이 정도 규모의 부하를 지원할 수 있는 전력 시스템을 단기간에 새롭게 구축하는 것은 “사실상 불가능하다”고 Constellation Energy Corp.의 CEO 조 도밍게즈(Joe Dominguez)는 말한다. Constellation은 마이크로소프트에 전력을 공급하기 위해 원자로를 재가동 중인 쓰리마일 섬(Three Mile Island) 핵발전소의 소유주다.
도밍게즈는 데이터센터 개발자들이 기존의 대규모 전력 자원, 예를 들어 자신이 운영하는 핵발전소와 같은 곳에 인접한 위치를 고려해야 한다고 강조한다. 핵발전소 몇 기 옆에 메가캠퍼스를 건설하고, 이를 재생에너지 자원과 배터리로 둘러싸며, 새로운 전선과 부하 전환 제어 시스템으로 이들을 모두 연결하면 독립형 전력망을 구축할 수 있다.
하루 수십억 리터의 물 사용
서버에 공급되는 전력은 모두 열로 변환된다. 과도한 열은 장비를 손상시키고 시스템 속도를 저하시킬 수 있다. 현재 데이터센터의 공기를 냉각하는 가장 에너지 효율적이고 비용 효율적인 방법 중 일부는 물을 사용하는 방식에 의존하고 있다. 블루필드 리서치(Bluefield Research)는 데이터센터가 에너지 생성 과정에서 사용되는 물을 포함하여 하루에 10억 리터 이상의 물을 소비한다고 추산했다. 이는 330만 명의 하루 물 공급량에 해당한다. 2023년 한 연구에 따르면, ChatGPT와 약 10~50개의 질문과 답변으로 이루어진 대화를 나누는 데 표준 16.9온스(약 500ml) 물병 하나 분량의 물이 필요하다고 추정됐다. ChatGPT의 초기 모델 중 하나를 훈련시키는 데만 약 200,000갤런(약 75만 리터)의 물이 소비된 것으로 추산된다. 문제를 더욱 악화시키는 것은 장비 손상과 환경 문제를 피하기 위해 대부분 음용 가능한 물을 사용한다는 점이다.
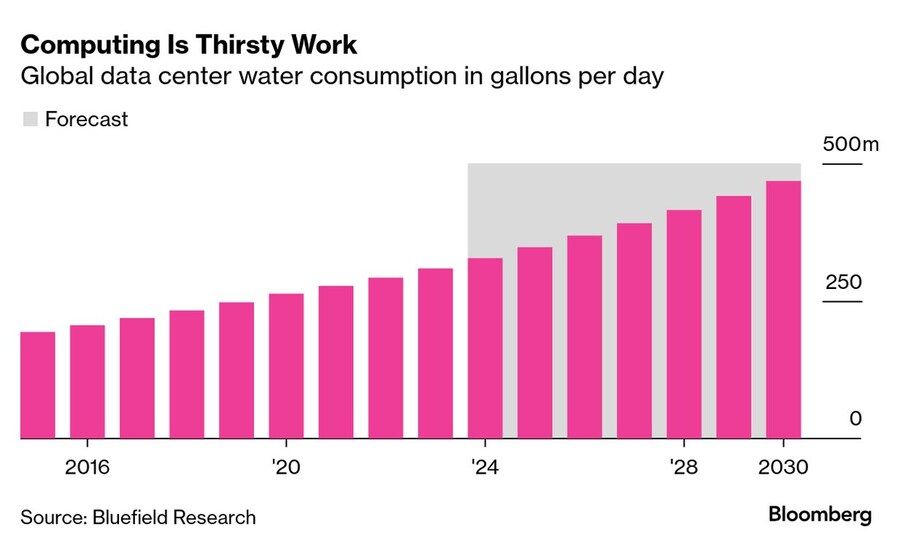
목마른 컴퓨팅
글로벌 데이터센터의 하루 물 소비량 (갤런 단위)
아이오와주 웨스트 데모인(West Des Moines)에서는 마이크로소프트가 운영하는 데이터센터 네트워크가 OpenAI와 협력하여 해당 지역에서 가장 많은 물을 사용하는 소비자로 떠올랐다. 물 관리국 자료에 따르면, 이 데이터센터는 도시 전체보다 더 많은 물을 소비하고 있다. (물 관리국은 마이크로소프트가 물 사용량을 크게 증가시킨 누수를 조사하고 있다고 밝혔다.)
스페인의 보리와 밀밭으로 둘러싸인 작은 도시 탈라베라 데 라 레이나(Talavera de la Reina)에서는 메타 플랫폼스(Meta Platforms Inc.)가 연간 약 6억 6,500만 리터(1억 7,600만 갤런)의 물을 사용할 예정인 데이터센터 건설 문제로 지역 주민들과 갈등을 빚고 있다.
두 배 더 많은 인터넷 대역폭
생성형 AI를 뒷받침하는 거대 언어 모델(LLM)은 인터넷을 통해 방대한 양의 데이터를 학습하며, AI 도구 사용자들도 이러한 수요를 더욱 증가시킬 것이다. AT&T의 CEO 존 스탱키(John Stankey)는 지난 5월, 네트워크의 무선 데이터 수요가 이미 연간 30% 증가하고 있으며, AI 사용 증가로 인해 이 추세가 멈추지 않을 것이라고 밝혔다. 그는 “연간 30~35%의 사용량 증가가 계속될 경우, 그 데이터를 처리하기 위해 더 큰 도로(네트워크)를 건설해야 한다”고 말했다.
버라이즌 커뮤니케이션스(Verizon Communications Inc.)는 지난 5년 동안 네트워크 트래픽이 두 배 이상 증가했는데, 이는 사람들이 비디오를 시청하고 스트리밍하는 데 더 많은 데이터를 사용했기 때문이라고 버라이즌 소비자 그룹 CEO 소미아나라얀 삼팟(Sowmyanarayan Sampath)이 비슷한 시기에 진행된 인터뷰에서 설명했다. 그는 향후 5년 동안에도 트래픽이 다시 두 배 증가할 것으로 예상하며, 이는 AI 모델에 입력되는 프롬프트와 데이터 덕분이라고 말했다. 삼팟은 “AI는 우리에게 다음 성장 동력이 될 것”이라고 강조했다.
기술 기업들은 광케이블 네트워크를 확보하기 위해 매우 적극적으로 움직이고 있다. 이에 따라 통신사 루멘 테크놀로지스(Lumen Technologies Inc.)는 지난 8월, AI 기반 연결 수요와 관련된 신규 사업에서 50억 달러를 확보했으며, 추가로 70억 달러 규모의 계약을 논의 중이라고 발표했다.
수천 개의 데이터센터를 위한 부동산
전 세계적으로 7,000개 이상의 데이터센터가 건설되었거나 개발 중이다. 이는 2015년의 3,600개에서 두 배로 증가한 수치다. 하지만 이마저도 부족할 가능성이 크다. ChatGPT 등장 이전에도 데이터센터 서비스에 대한 수요는 급격히 증가하고 있었는데, 이는 기업들이 점점 더 데이터 처리를 자체 시설이 아닌 원격 클라우드 서비스로 이전했기 때문이다. 게다가 모든 주요 국가들은 자국 내 AI 허브를 구축하려고 하면서 글로벌 인프라 경쟁이 가속화되고 있다.
데이터센터는 넓은 부지를 필요로 한다. 예를 들어, 데이터센터 중심의 부동산 투자 신탁 회사인 에퀴닉스(Equinix Inc.)는 수백 메가와트 규모의 캠퍼스를 위해 200에이커의 토지를 매입했다. 또 다른 회사는 기가와트 규모의 데이터센터 개발을 위해 2,000에이커의 토지를 임대 개발 계약으로 확보했다. 데이터센터의 전력 요구를 충족할 수 있는 적합한 부지를 찾는 것은 매우 어려워 입찰 전쟁을 촉발시키고 있다.
이러한 대규모 단지는 건설 자재와 이를 설치할 인력도 필요하다. 하지만 자재는 주문 적체 상태에 있으며, 숙련된 노동자도 부족한 상황이다. 한편, 클라우드 서비스 제공업체 CoreWeave의 브라이언 벤투로(Brian Venturo)는 일부 고객들이 전체 캠퍼스를 자신들의 사업에만 사용해달라고 요청하고 있다고 말했다. 그는 “역사적으로 물리적 비즈니스를 지원해 온 공급망보다 시장이 훨씬 빠르게 움직이고 있다”고 설명했다.
끝없는 반도체 수요
그래픽 처리 장치(GPU)는 AI 모델을 훈련하는 데 필수적인 핵심 장비다. GPU는 수천 개의 작업을 동시에 처리할 수 있도록 설계되었으며, 이를 병렬 처리(parallelism)라고 부른다. 데이터센터는 수백 개에서 수천 개에 이르는 이러한 프로세서를 사용하며, 각각의 가격은 가족용 자동차보다도 비싸다. 생성형 AI 붐이 시작되었을 때 거의 모든 주요 기술 기업들이 이 유형의 칩 부족 문제를 겪었다. 마이크로소프트와 구글은 과거 실적 발표에서 GPU 재고 부족이 주요 과제 중 하나라고 언급하기도 했다.
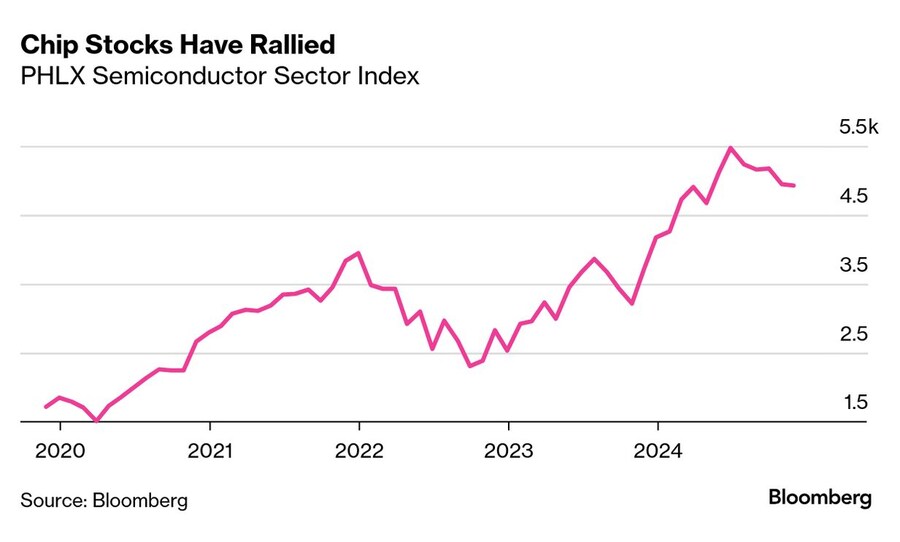
반도체 관련 주식의 상승세
필라델피아 반도체 섹터 지수
엔비디아(Nvidia Corp.)는 매년 새로운 기술을 출시하는 전략으로 시장 경쟁을 더욱 치열하게 만들었다. 이로 인해 이미 압박받고 있는 공급망에 추가적인 부담이 가중되고 있다. 엔비디아는 11월에 발표한 새로운 블랙웰(Blackwell) 제품이 예정보다 빠르게 생산 궤도에 올랐다고 밝혔다. 하지만 중요한 점은 모든 수요를 충족하기까지는 아직 수분기가 더 걸릴 것이라는 점이다.
실리콘, 철강, 석영, 그리고 구리
앞서 언급한 많은 항목들은 금속과 광물을 필요로 한다. 그중에서도 칩, 회로, 프로세서의 기초가 되는 실리콘을 생각해보자. 중국은 원자재 실리콘과 정제된 실리콘 소재의 최대 생산국이며, 이는 중국과 미국 및 그 동맹국 간의 긴장이 고조되면서 우려를 낳고 있다. 최근 공급망 위기는 노스캐롤라이나주에서 발생했다. 10월, 허리케인 헬렌(Hurricane Helene)은 미국 동부 전역에서 수십 명의 생명을 앗아가고 수많은 사람들을 고립시키는 동시에, 주 내에서 최고 품질의 석영을 생산하는 두 광산의 운영을 방해했다. 이 두 광산은 세계 최고 품질 석영의 약 80%를 생산하는데, 석영은 실리콘을 가열·용융·재구성하여 반도체 제조에 이상적인 단결정(single-crystal) 구조를 만드는 도가니(crucible)를 생산하는 데 사용된다.
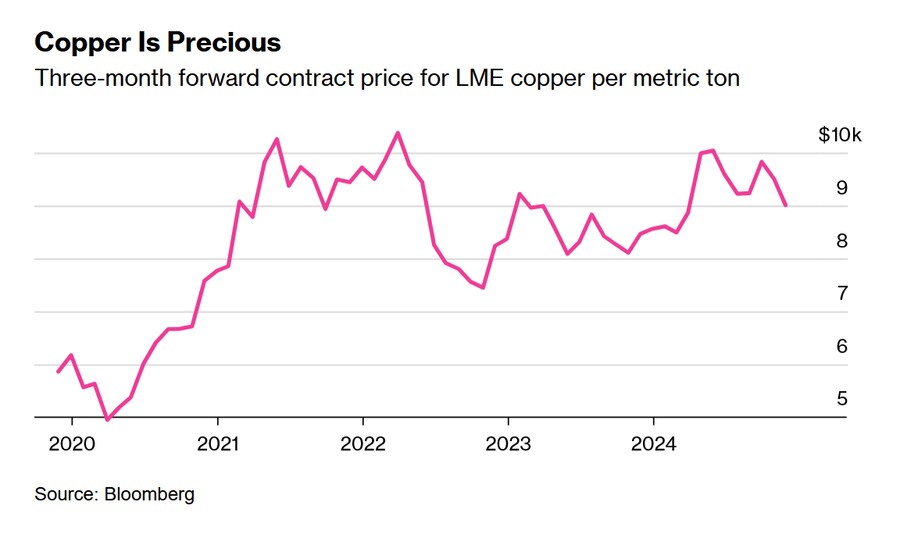
구리는 귀하다
LME 구리 3개월 선물 계약 가격 (톤당)
반도체에는 금, 은, 알루미늄, 주석이 포함되어 있다. 이러한 금속들은 현재 공장 가동을 유지할 만큼 충분한 양이 있다. 그러나 두 가지 생소한 반도체 금속, 갈륨(gallium)과 저마늄(germanium)이 새로운 병목 현상의 잠재적 원인으로 부상하고 있다. 12월, 중국은 미국과의 기술 전쟁 격화의 일환으로 이 두 금속의 수출 금지를 발표했다.
구리는 칩, 데이터센터, 전기 장비, 냉각 유닛 등 거의 모든 곳에 사용되고 있어, AI, 재생 에너지, 전기 교통 분야 간의 수요 경쟁을 촉발할 잠재력을 지니고 있다. 여기에 데이터센터 건설과 케이블 같은 인프라에 필수적인 철강도 있다.
세계에 존재하는 것보다 더 많은 (고품질) 데이터
생성형 AI 모델은 인간이 음식을 필요로 하듯 고품질의 데이터를 필요로 한다. 대규모 언어 모델(LLM)은 텍스트를 소위 토큰(token)이라 불리는 작은 단위로 나눠 “훈련”된다. 이 텍스트에서 LLM은 반복적으로 패턴을 식별하고, 특정 텍스트 뒤에 어떤 텍스트가 이어져야 하는지를 예측하는 과정을 거친다. 세계 최고의 LLM들은 각각 1조 개 이상의 토큰으로 훈련되었다. 이를 맥락 속에서 이해하자면, 약 2,048개의 토큰이 1,500단어 정도에 해당한다. 전 세계에 누적된 텍스트 데이터의 총 토큰 수에 대한 추정치는 몇 조에서 수천 조에 이르기까지 다양하다.

Bloomberg Markets의 12월/1월 호에 실린 기사. Carolina Moscoso의 일러스트레이션
놀랍게도, 이러한 풍부한 데이터조차 일부 사람들이 희망하는 만큼 AI 개발을 신속하게 진행하는 데 충분하지 않을 수 있다. OpenAI와 같은 세계에서 가장 강력한 AI 모델 개발자들조차 새로운 고품질의, 인간이 만든 훈련 데이터를 찾는 데 점점 어려움을 겪고 있다.
비영어권 언어 데이터는 한정되어 있고, 서구 또는 백인 사회 중심이 아닌 데이터는 더욱 부족하다. 이러한 다양성 부족은 소수민족, 여성, 기타 대표성이 낮은 집단에 대해 편향적인 AI 제품을 초래할 위험이 있다. 예를 들어, Bloomberg가 올해 실시한 분석에 따르면, ChatGPT의 기본 AI 모델은 이름만을 기반으로 이력서를 평가할 때 특정 인종 집단에 대해 편향을 나타내는 것으로 나타났다. OpenAI는 이러한 결과가 자사 고객이 모델을 사용하는 방식을 반드시 반영하지 않을 수 있으며, 잠재적 위해를 식별하기 위해 노력하고 있다고 밝혔다.
데이터와 콘텐츠를 생산하는 언론사나 금융기관 같은 단체들은 자신들의 정보가 AI 개발자들에게 점점 더 가치 있는 자산이 되고 있음을 인식하고 있다.할리우드 배우와 작가들은 2023년에 자신들의 창작물을 기술로부터 보호하기 위해 파업에 나섰다. 뉴욕 타임스(New York Times)와 주요 음반사는 AI 기업들이 저작권이 있는 작품을 훈련 데이터로 사용하는 것에 대해 소송을 제기했다. AI 기업들은 공개적으로 이용 가능한 자료를 훈련에 사용하는 것이 법적으로 허용된 공정 사용(fair use)이라고 주장한다.
S&P Global Inc.의 CEO 마르티나 청(Martina Cheung)은 최근 투자자들과의 통화에서 이렇게 요약했다. “대규모 언어 모델은 훈련받은 데이터의 품질과 양에 따라 결정되며, 우리에게는 고품질 데이터가 많습니다.” 실제로 OpenAI는 지난 1년 동안 뉴스 코퍼레이션(News Corp.), 콘데 나스트(Condé Nast), 허스트(Hearst), 레딧(Reddit), 피플 매거진(People Magazine) 발행사 닷대시 메레디스(Dotdash Meredith), 악셀 슈프링거(Axel Springer)와 같은 단체의 콘텐츠를 사용하기 위해 계약을 체결했다.
기술 기업들은 AI가 만든 자체 콘텐츠로 구성된 "합성" 데이터세트를 활용해 모델을 훈련하는 실험을 하고 있다. 이론적으로 이는 AI 기업들이 데이터에 대한 무한한 수요를 충족시키는 동시에 웹에서 정보를 스크랩하는 데 따른 법적, 윤리적, 프라이버시 관련 문제를 피할 수 있도록 돕는다. 하지만 일부 연구자들은 AI 모델이 인간이 아닌 AI가 생성한 콘텐츠로 훈련될 경우 “붕괴”할 수 있다고 경고한다. 2023년에 발표된 이른바 모델 붕괴(model collapse)에 관한 논문에 따르면, AI 모델이 "자신이 만든 데이터를 소량만 다시 학습하더라도" 생성된 인간 이미지가 점점 더 왜곡되었다.
어쩌면, 사람들이 두려워하거나 기대했던 것보다 적을지도 모른다
투자자, 데이터센터 운영자, 에너지 기업 및 기타 비즈니스들이 AI에 필요한 공급망의 다양한 부분에 집단적으로 수천억 달러를 투자하고 있다. 주요 은행과 사모 금융업체는 1조 달러에 이를 것으로 추산되는 AI 인프라 지출에서 한 몫을 차지하기 위해 포지셔닝하고 있다. 알파벳(Alphabet), 아마존(Amazon), 메타(Meta), 마이크로소프트(Microsoft)의 자본 지출은 2024년에 총 2,000억 달러를 초과할 것으로 예상된다.
S&P 500 유틸리티 섹터 지수는 지난 1년 동안 22% 상승했으며, 데이터센터 중심의 REIT(부동산투자신탁) 기업인 에퀴닉스(Equinix)는 2022년 말 이후 시가총액이 거의 두 배로 증가했다. 엔비디아(Nvidia)의 주가는 지난 2년 동안 약 700% 급등하며, 이 회사를 세계에서 가장 가치 있는 기업 중 하나로 만들었다.
그러나 결국 AI가 계속 성장할지 여부는 아무도 알 수 없다. 월가의 일부 애널리스트들은 현재의 열풍이 끝날 것이라고 예측하기 시작했다. 투자자들은 빅테크(Big Tech)의 막대한 지출이 그들이 상상했던 AI 수익 모델을 실현할 수 있을지 의문을 제기하고 있다.
수천억 달러가 투자되는 AI에 대한 가장 큰 위협은 세계에서 가장 앞선 모델 개발자들과 그들의 공급업체들이 효율성에 집착하고 있다는 점일지도 모른다.
반도체 장비 제조업체인 어플라이드 머티어리얼즈(Applied Materials Inc.)의 CEO인 게리 디커슨(Gary Dickerson)은 11월 투자자들에게 일부 AI 기업들이 향후 5년 내에 컴퓨팅 효율성을 "100배 개선"하는 것을 목표로 하고 있다고 말했다. 또 다른 기업들은 15년 내에 1만 배 개선을 목표로 하고 있다고 한다. 디커슨은 "효율성은 업계를 하나로 묶는 주된 원동력으로 떠오르고 있다"고 강조했다.